If you’ve browsed the web for any amount of time, you’ve likely had your humanity questioned. A challenge is presented to assert whether or not you are human. A CAPTCHA, or Completely Automated Public Turing test to tell Computers and Humans Apart (a.k.a. my favorite acronym of all time), is the technical term for this challenge. As a software developer, I have been looking into different solutions to fraud prevention in my own personal coding projects. That’s why today’s Pondering will be discussing why CAPTCHAs exist, if they work, and what the future holds for them.
Origin
During the dawn of the World Wide Web, the landscape was completely different. I’m sure I don’t have to tell you that. The idea of using the internet to order your Venti, Extra-Hot, Light Milk Foam, 2 Pumps Vanilla, 2 Pumps Caramel, Oatmilk Caffè Latte for pickup was not even on the radar at the time. Sir Tim Berners-Lee, a living legend who deserves far more fame and appreciation than he currently has, invented the World Wide Web with the idea of it being based on document serving and management. Think of it as if every page on the internet was a Wikipedia entry. You request a document, and a document is returned. It’s a romantic idea by today’s standards, where most of the data of articles on the internet are mostly ads and trackers, with just a few kilobytes being the actual content requested.¹ I mean no disrespect to those authors and websites, as it’s their revenue stream, but it’s undeniable that it strays from the original vision for the web. My point is to say that the web has changed and evolved, and that has presented many challenges. One of the first challenges was preventing automated scripts from polluting the databases and servers of the newly born web.
The invention of the CAPTCHA is a bit fuzzy as there is controversy as to who was the first to conceive the idea, but maybe that’s for the best. After all, anyone who claimed to invent the box that repeatedly asks you to type words and identify fire hydrants would likely have pitchforks immediately aimed in their direction. Regardless of patents and terminology, the first concrete implementation of a web-based CAPTCHA was in 1997 by AltaVista, an early search engine. They implemented CAPTCHAs to limit the automated submission of URLs to their database and the manipulation of search rankings.²
Concept
To keep things simple, I’ll give an example. Let’s say you have an outdoor garden growing various fruits and veggies. Recently, swarms of crows have been swooping in and eating some of your harvest. You want to keep the crows out, but you still need to be able to access the garden to water and harvest the plants. As a solution, you put the garden inside of a greenhouse. Now, the crows can’t reach the garden while you still can. In this example, the gardener is a human user, the swarms of crows are automated bots, the garden is some internet resource (i.e. a database), and the greenhouse is the CAPTCHA. Notice how I didn’t say whether the greenhouse had a lock or not. The purpose of a CAPTCHA is to determine whether or not the user is human, not to check their authorization or their intentions. A human thief could still walk into the greenhouse and steal some of the harvest. The difference between the human thief and the crows is the sheer amount of crows there will be in comparison.
Limitations
What about limitations? There are a few. As Tom Scott points out, CAPTCHAs only need to check if there is a human in the loop.³ A bot can fill out the entirety of a form in less than a second just to send the CAPTCHA challenge to a human for them to complete.⁴ CAPTCHAs also won’t stop malicious human activity, they only discourage it. If a human wants to manually fill out the same form 5,000 times, they can. The CAPTCHAs may become more intrusive and difficult, but their job is to only determine if the user is human, not what their intention is. The challenges themselves are also only checking for “human answers,” not correct answers. There may be times when what the CAPTCHA is asking for is ambiguous. For example, being asked to select all boxes containing bikes, when both bikes and motorcycles are present. There is no truly correct answer, just a human answer.
Evolution
But how effective are CAPTCHAs? That answer has changed drastically with time, but it’s safe to say that no solution is 100% effective.
ReCAPTCHA v1 was a clever way of handling the CAPTCHA challenge. It displayed two distorted words: one word was known and the other was unknown, taken from a scan of a newspaper or book. The human would type both. If the human types the known word, they have verified they’re human. Based on that, the other word would be logged. If enough humans type the same answer to that unknown word, the scanned word would become known. It was a smart way of digitizing old books and newspapers while also preventing fraud. It proved extremely effective based on the sheer number of people who completed these challenges. However, with the advent of A.I. and machine learning, reading distorted text, CAPTCHAs needed to change.
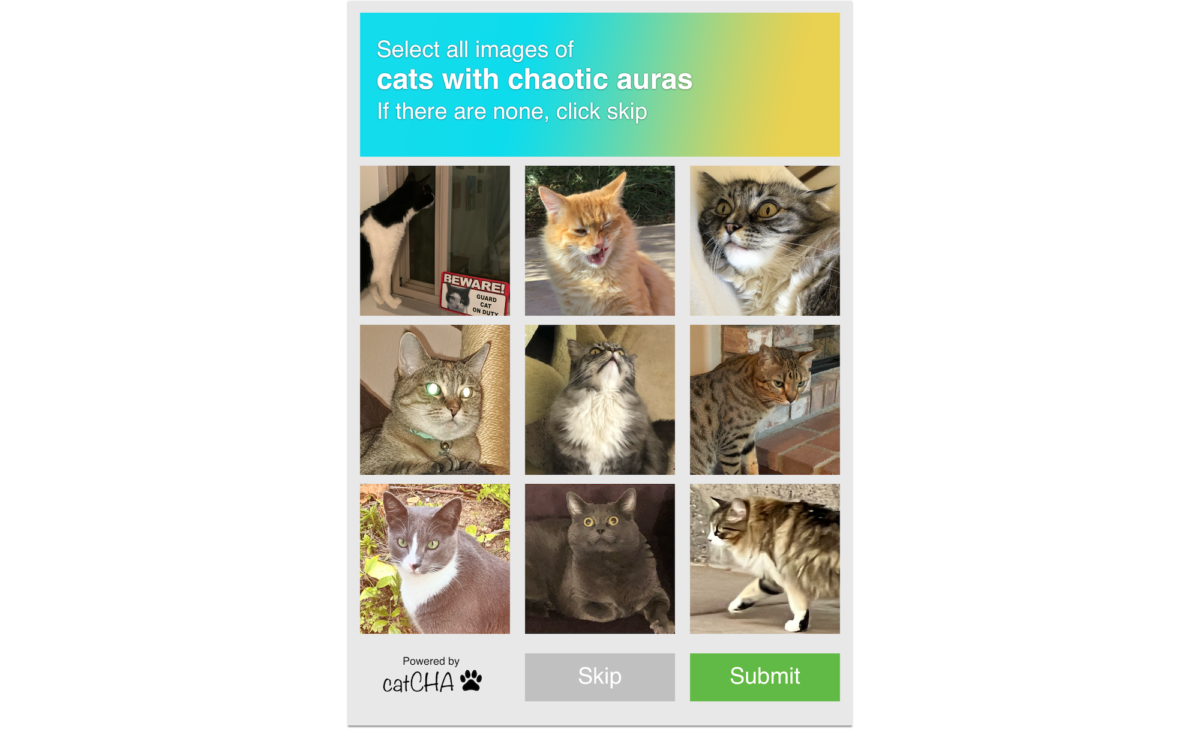
As CAPTCHAs adapt to evolving bots, they become more intrusive towards humans. At this point, ReCAPTCHA was owned by Google, so it evolved in a very Google-like way. ReCAPTCHA v2 is the standard “I’m not a robot” checkbox we know today. Based on your behavior on a website, and combined with behavior patterns likely derived from the Google tracking cookies from around the web, ReCAPTCHA v2 assigns you a score on how likely you are to be human. If it believes you’re a human, you’ll be able to check the box without any interruption. Otherwise, you’ll be presented with a CAPTCHA challenge, typically consisting of a prompt and nine images. Despite the drastic change in how CAPTCHAs are presented, the bots would still adapt.
Many of these picture-based CAPTCHAs from Google are often of streets taken from Google Maps. While Google has denied that they’re using this data for training their self-driving cars⁵, I can’t help but ponder the possibilities that would bring. While not the case today, Waymo (owned by Google) has historically held the first place title for California DMV Disengagement Reports for several years. Disengagement is when a self-driving car calls upon its driver to take the wheel, something we want to minimize. In 2020, Waymo had nearly 30,000 miles of autonomous driving per disengagement. In comparison, Nissan, the highest “traditional” car maker on the list, had just under 100 miles per disengagement that same year.⁶ With numbers like those, one can’t help but wonder if Google does use these CAPTCHAs to better self-driving cars.
That said, this hypothetical would be a double-edged sword, in that by making their self-driving cars better, Google would also be making current CAPTCHAs less effective. There is a two-pronged effect that is posited by von Ahn et al.⁷
“any program that has high success over a CAPTCHA can be used to solve an unsolved Artificial Intelligence (AI) problem”
CAPTCHA: Using Hard AI Problems for Security
If such a program can rise to the challenge of consistently solving an unsolved CAPTCHA, an A.I. challenge has effectively been solved. We’ve seen this already, from reading distorted text to identifying objects from images. This has become so trivial to computers that smartphones can do this on the fly. It’s for this reason CAPTCHAs have become more intrusive and, at times, difficult. So where do we go from here?
Private Access Tokens
As we look to the (hopefully) near future, Private Access Tokens seem to be the next big thing. They were promoted by Apple at their annual Worldwide Developers Conference this year, though they are an open standard that can be used by any platform.⁸ Private Access Tokens are a new open standard that allows users to bypass CAPTCHA challenges if their device can attest that its hardware is genuine and its user is human on their behalf. The idea is that if you’re accessing a website on something like your phone, you’ve performed actions that would be hard for a bot to replicate. These can include having a physical phone (as opposed to being in a virtual machine), authenticating with biometrics, and being signed in on your phone to Apple or Google. If the hardware manufacturer can attest that the hardware was not modified to falsify these actions, the website can be fairly certain that a human is accessing its site. All of this occurs in the background without the need to prompt users. It also has the potential to be much more accessible and privacy-centric than today’s CAPTCHAs. No need to track users and no reliance on visual or auditory queues to complete a CAPTCHA with this method, provided it’s used responsibly. Of course, I have no doubts that bot makers will rise to the challenge, as they have before.
Conclusion
While CAPTCHAs can be a fun puzzle the first time, they can be a chore the 5,000th. They are necessary to help prevent automated fraud but are annoying barriers to clear for legitimate users. Personally, I view innovation as finding a new way to do something in a better way and hopefully Private Access Tokens can live up to the promises they’ve made and can get adopted throughout the web. Regardless, there will always be a need for an accessible and accurate Turing test to help make the web a bit tidier.
Notes and Citations
¹ I was unfortunately unable to find a source to back this statistic. This is based on my own basic research on a very small sample of articles.
² Soto, M. (2019, May 24). The origin of CAPTCHA and reCAPTCHA. tipsmake.com. Retrieved October 2, 2022, from https://tipsmake.com/the-origin-of-captcha-and-recaptcha
³ Tom Scott has a great video on this topic and I highly recommend watching it if you’re interested in CAPTCHAs.
⁴ This isn’t necessarily true for all CAPTCHAs. Google’s “I am not a Robot” CAPTCHA challenge uses many different factors to assign a confidence score to its users. We don’t know what goes into that score, but things like how quickly the form was filled out is likely one of them.
⁵ Vega, E. (2021, May 14). Why captchas are getting harder. Vox. Retrieved October 2, 2022, from https://www.vox.com/22436832/captchas-getting-harder-ai-artificial-intelligence
⁶ Herger, M. (2021, February 10). 2020 disengagement reports from California. The Last Driver License Holder… https://thelastdriverlicenseholder.com/2021/02/09/2020-disengagement-reports-from-california/
⁷ von Ahn, L., Blum, M., Hopper, N.J., Langford, J. (2003). CAPTCHA: Using Hard AI Problems for Security. In: Biham, E. (eds) Advances in Cryptology — EUROCRYPT 2003. EUROCRYPT 2003. Lecture Notes in Computer Science, vol 2656. Springer, Berlin, Heidelberg. https://doi.org/10.1007/3-540-39200-9_18
⁸ If you’re tech savvy and interested in learning more about Private Access Tokens, I highly recommend watching Apple’s WWDC22 talk on the subject.
One reply on ““I, Robot?” – A Short Thesis on CAPTCHAs”
Wow, you took something very technical, broke it down and made it a very enjoyable read. It will be fun to come back and read this in 5 or 10 years and see how web security has evolved.